循序渐进:PRISMA 2009流程图

Step 1: Preparation 要完成棱柱图,请打印一份该图的副本,以便与您的搜索一起使用。可从以下地址下载 the PRISMA website 您将需要打印所有数据库的总计副本,但是您可能还希望为搜索的每个数据库打印一份副本。如果您正在使用该系统进行更高级的分配,请询问您的主管他们是否希望您遵循该系统,或者在最终的PRISMA图中为每个数据库指定总计。
Step 2: Doing the database search 对于每个数据库,分别输入每个关键搜索词。这应该包括您所有的搜索词,包括MeSH或其他主题词,省略(例如hemipleg *)和/或通配符(例如sul?ur)搜索词。适当地使用布尔运算符(例如AND或OR)将所有搜索词组合成不同的组合。应用您的所有限制(例如搜索年份,仅英语等)。合并所有搜索词并应用所有相关限制后,您应该拥有许多记录或文章。在每个数据库的PRISMA流程图的左上方框中输入此内容。如果您已分别搜索数据库,则将所有“已识别的记录”加起来,并在PRISMA流程图中填写该总数,将用于您的课程。请记住,如果您分别搜索数据库,则在每个步骤中都需要重复此过程,将单个数据库搜索中的记录总数加起来总计。

Step 3: Additional sources 如果您通过数据库以外的其他来源识别了文章(例如,通过找到的文章的参考列表进行手动搜索,或通过诸如Google Scholar这样的搜索引擎进行搜索),请在流程图右上方的框中输入记录总数。

Step 4: Remove all duplicates 为避免查看重复文章,您需要删除任何出现多次的文章。您需要通过数据库中找到的所有记录或文章进行,并手动删除任何重复项。您将需要遍历数据库中找到的所有记录或文章,并手动删除所有重复项。如果此时您有大量文章,那么这样做并不容易。在这种情况下,您可能希望将整个文章列表导出到引文管理器,例如EndNote,Sciwheel,Mendeley或Zotero(包括文件中的引文和摘要),然后删除其中的重复项。在您从顶部的第二个框中删除重复的副本后,输入剩余的记录数。
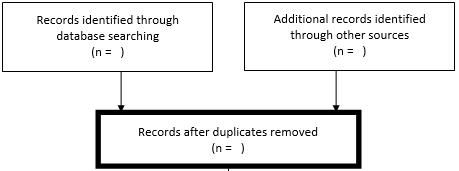
Step 5: Screening articles 下一步是添加您已筛选的文章数。此数字与您在“重复删除”框中输入的数字相同。
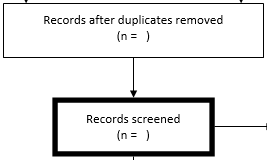
Step 6: Screening - Excluded articles 现在,您需要筛选与您的研究问题相关的文章的标题和摘要。 任何看来有助于您提供研究问题答案的文章都应包括在内。记录基于此筛选过程中排除的文章数量(在筛选记录的总数旁边),包括排除这些文章的简短原因。
Step 7: Eligibility 从筛选的记录总数(步骤5)中减去筛选阶段(步骤6)后排除的文章数,并在标题为““Full-text articles assessed for eligibility”的框中输入该数目。获取这些文章的全文以进行资格审查。您可以通过馆际互借请求文章,以确保您获得最多的研究。
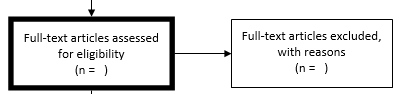
Step 8: Eligibility - Records excluded 审查所有全文文章的资格,以将其包括在最终审查中。在这里记下您要排除的文章数量,并在正确的标题框中输入这个数字:全文文章排除,然后写一个排除这些文章的简短理由(这可能与筛选阶段使用的理由相同)。例子包括错误的设置,错误的患者人数,错误的干预,错误的剂量等等。
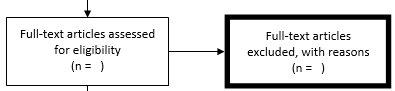
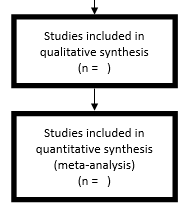
Step 9: Included 最后一步是从为资格审查的文章总数(步骤7)中减去全文资格审查(步骤8)期间排除的文章或记录的数量。在定性综合框中输入该数字。如果执行荟萃分析,您还将在定量合成框中列出研究数量。现在,您已经完成了PRISMA流程图,您现在可以将其包括在文章或作业的结果部分中。
附件:官网下载